Пятница, 12 Октября 2012 г.
08:32 the_Dark_One
Краткий перебой в работе джорналз не помешает нам напомнить о том, что продолжается запись на участие в нашем чисто дневниковском, уютном календаре на 2013 год. Участие в нём бесплатное и ни к чему не обязывающее, это just for fun. Единственное условие - все съёмки проводятся в городе Москва, тут уж ничего не поделать.
Тема календаря - "Достижение камрада!"
Тут на ваше усмотрение. Что случилось с вами в 2012 году интересного? Вы завели семью/ребёнка/любовника? Интересно путешествовали или переехали на ПМЖ в Арабские Эмираты? Купили новый китайский внедорожник, восторгам от которого нет предела? Перешли на новую работу или сменили сферу деятельности? Поймали рыбу с вооот такими глазами? Взяли кредит на квартиру и сделали своими руками ремонт? Настолько затравили недруга, что он сбежал с ресурса и живёт с ноутбуком в лесу? У вас появился настоящий КОТ?
Спешите поведать об этом миру!

Покамест, выразили желание поучаствовать:
* Sheypa
* Soul и Lelik (* есть планы заехать в Москву?)
* 3 CaHuTaPa (* есть планы заехать в Москву?)
* Еще одна Кошка
* Hamaan
* Grimble
* Afterlife
* Несмеяна
* ещё один участник подал заявку, но думает
Смелее, друзья! Записываемся!
Тема календаря - "Достижение камрада!"
Тут на ваше усмотрение. Что случилось с вами в 2012 году интересного? Вы завели семью/ребёнка/любовника? Интересно путешествовали или переехали на ПМЖ в Арабские Эмираты? Купили новый китайский внедорожник, восторгам от которого нет предела? Перешли на новую работу или сменили сферу деятельности? Поймали рыбу с вооот такими глазами? Взяли кредит на квартиру и сделали своими руками ремонт? Настолько затравили недруга, что он сбежал с ресурса и живёт с ноутбуком в лесу? У вас появился настоящий КОТ?
Спешите поведать об этом миру!
Покамест, выразили желание поучаствовать:
* Sheypa
* Soul и Lelik (* есть планы заехать в Москву?)
* 3 CaHuTaPa (* есть планы заехать в Москву?)
* Еще одна Кошка
* Hamaan
* Grimble
* Afterlife
* Несмеяна
* ещё один участник подал заявку, но думает
Смелее, друзья! Записываемся!
Группы: [ Встречи ]
[ Другая полезная информация ]
[ Опросы ]
[ Происшествия ]
[ Сенсации ]
[ Скандалы ]
[ Служебная запись ]
[ Титаны наших дней (личности) ]
[ Флэш-моб ]
Комментарии [15]
Вторник, 13 Декабря 2011 г.
01:06 the_Dark_One » Об'явление!

Cписок камрадов, поучаствовавших в создании календаря:
* 3 CaHuTaPa
* Корней
* nut
* the_Dark_One
* Necroscope
* Free Frag
* Major Pronin
* Super Castor
* MMM
* <секрет>
* <секрет>
* <секрет>
Как видите, мы не раскрываем всех наших "звёздных мальчикофф", так как:
а) часть кандидатур в ходе создания календаря поменялась,
б) на календарь отщёлкано более 15-ти камрадов, что никак не соответствует числу месяцев в году; а потому у нас был выбор.
в) умело пущены слухи о пуле кандидатур на секретных три месяца.
Мы оставляем себе право на небольшую интрижку, кто же эти три оставшихся товарища на календарных страничках. :)
PS:

Группы: [ Встречи ]
[ Другая полезная информация ]
[ Игры и конкурсы ]
[ Интересное за неделю ]
[ Опросы ]
[ Происшествия ]
[ Сенсации ]
[ Скандалы ]
[ Служебная запись ]
[ Титаны наших дней (личности) ]
Среда, 12 Октября 2011 г.
08:01 the_Dark_One » Календарь
В прошлом году сообщество было несказанно обрадовано мегакалендарём с прекрасными местными отроковицами.
Есть идея повторить, в этот раз - порадовать женский пол местным мужским телом.
Что скажете, хороша идейка?
Поучаствовать, хоть и советом - не желаете?
Если что, обсуждение - в том числе и тут:
http://journals.ru/journals_comments.php?id=3779934
Есть идея повторить, в этот раз - порадовать женский пол местным мужским телом.
Что скажете, хороша идейка?
Поучаствовать, хоть и советом - не желаете?
Если что, обсуждение - в том числе и тут:
http://journals.ru/journals_comments.php?id=3779934
Акция вполне себе НЕ шуточная (хоть и с долей юмора), фотографии планируются студийно-качественные, календарь нарядный.
Всех делов-то - предложить, кого вы хотели бы видеть на календаре, и если предложенная кандидатура не возражает, то приехать на фотосессию.
Если соберём 12 злобных зрителей мужиков и отснимем их в ноябре, в декабре всё будет отпечатано и роздано всем желающим и заинтересованным.
Уже предложены (зачёркнутые - отказались):
никакого сбора средств на сомнительные расчётные счета не будет, мы не нищеброды, идею сами проспонсируем. Участники получат по бесплатной версии, прочие желающие смогут купить календарик по относительно неграбительской цене.
В этом году - нормальный календарь от людей с опытом в полиграфии!
Тут уже звучали кандидатуры (зачёркнуто - отказались, со звёздочкой - не против):
Корней
Dolphin
Милославский
Yarvoh
chicago
S Castor*
3 CaHuTaPa*
Герр Зайчег
AleХХ*
Mostack
MMM
Великий Коммендаторе*
Free Frag*
Biker
nut*
tarik
Гуннбьёрн
Zhe
Sakha
Маjor Pronin*
the_Dark_One*
Wild*
Alexvn
morbid*
Upd: Идея календаря принадлежит vorvirgo, она отличный фотограф, готова поснимать киевлян (скоро будет в ваших краях) и москвичей в студии. То есть, проект в надёжных руках.
Ну и я помогу чем смогу.
Группы: [ Встречи ]
[ Другая полезная информация ]
[ Другие дневники ]
[ Другие клубы ]
[ Игры и конкурсы ]
[ Интересное за неделю ]
[ Опросы ]
[ Полезные ссылки и программы ]
[ Происшествия ]
[ Сенсации ]
[ Скандалы ]
[ Служебная запись ]
[ Титаны наших дней (личности) ]
[ Флэш-моб ]
Вторник, 22 Марта 2011 г.
10:10 Mikki Okkolo » Объявление
На всякий случай напоминаю и поясняю, кто не в курсе:
Клуб общественный, стать участником и публиковать объявления, заявления и прочие явления может любой желающий, в соответствии с правилами.
Клуб общественный, стать участником и публиковать объявления, заявления и прочие явления может любой желающий, в соответствии с правилами.
Группы: [ Служебная запись ]
Комментарии [4]
Пятница, 4 Марта 2011 г.
15:13 Mikki Okkolo » Объявления
1) Конкурс на потс месяца не удался . Все в спячке.
Так шта волюнтаристки объявляю лучшей записью февраля объявлю лучшей вот эту запись Привета . Призовые календари торжественно убираю в чулан.
2) Добрые люди изготовили кнопки-призы для победителей предыдущих конкурсов.
Означенные победители могут использовать эти кнопки по своему усмотрению (или не использовать)
Итак:
Алекс Лочер в номинации "Проект года 2010"

Победитеди конкурса 2008
Так шта волюнтаристки объявляю лучшей записью февраля объявлю лучшей вот эту запись Привета . Призовые календари торжественно убираю в чулан.
2) Добрые люди изготовили кнопки-призы для победителей предыдущих конкурсов.
Означенные победители могут использовать эти кнопки по своему усмотрению (или не использовать)
Итак:
Алекс Лочер в номинации "Проект года 2010"
Победитеди конкурса 2008
Четверг, 10 Февраля 2011 г.
09:13 События » Пошаговая инструкция, как свой дневник занести в анналы.
Благодарности камрадам: the_Dark_One, MMM, бабер (ака ZaRRaZZa)
Часть первая.
1) Нам потребуется веб-браузер Mozilla Firefox и плагин к нему, Scrapbook. Если не установлены - идём по ссылкам и качаем.
2) Настраиваем место для сохранения нашего архива. В Mozilla Firefox: Инструменты - Дополнения - Scrapbook 1.3.7 - Настройки. Закладка "Организация". Расположение сохраняемой информации - "Сохранить информацию в". Выбираем папку под архив дневника.
3) Заходим в блог через Firefox под своей учётной записью.
4) Определяем, сколько страниц в дневничке уже набалаболено: отправляемся к истокам собственного блоговодства и запоминаем номер последней страницы.
Хинт: На странице своего дневника. Кабинет - Настройки сайта - Общие. Разбиение на страницы / столбцы, в пункте "Записи" ставим значение 25. Меньше мороки будет. Число страниц моего бложека с 498 по умолчанию успешно сократилось до 398.
Часть вторая.
5) Делаем в дневнике рабочую запись со ссылками на все страницы дневника (главная + &page=2, 3 и т.д.).
Хинт: Воспользуемся Excel'ом.
Столбец А: пишем в первую ячейку "1", дальше выделяем в этом столбе строки с первой по 398-ую (т.е. по номеру вашей последней страницы), используем автозаполнение с шагом в единицу (главная - заполнить - прогрессия).
Столбец B: в первую строчку пишем "http://www.journals.ru/journals.php?userid=17348&page=". Дублируем в каждой строчке по 398-ую (последнюю).
Cтолбец С: Пишем текстовую формулу (так же в каждую строчку) "=СЦЕПИТЬ(B:B;A:A)".
Готово. Осталось только скопировать полученное в третьем столбце в запись. Захраняем рабочую запись.
6) Открываем запись в режиме "для печати". (В нижнем правом углу ссылка "Print", если вы её не переименовывали в текстовых настройках дизайна дневника).
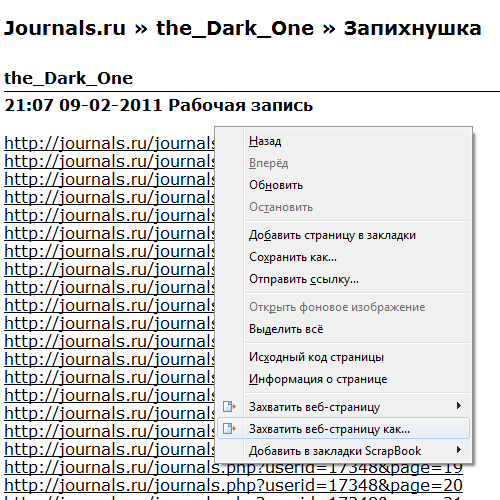
Часть третья.
7) Scrapbook'ом сохраняем эту запись. Для чего щёлкаем правой кнопкой мыши по любому пустому месту на записи и выбираем "Захватить веб-страницу как...". Далее:
* Cоставные части страницы: изображения, css-стили.
* Поле "Загрузка содержимого по ссылкам на странице" - отмечаем, планиуем ли грузить всяческие изображения, аудиофайлы, архивы, видео и т.п. Я для себя отметил только изображения.
* Уровень глубины захвата ссылок - 3. Ненужное мы отсечём фильтром.
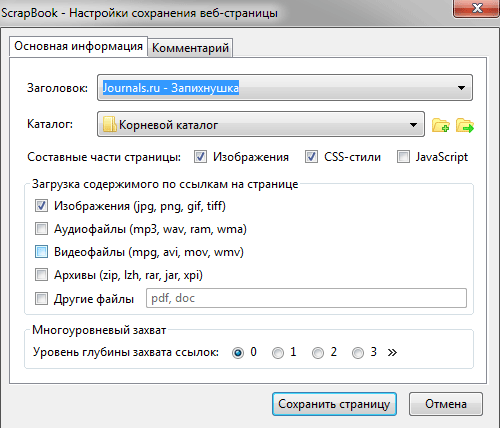
* Жмакаем "сохранить страницу" и попадаем в новое окно. На нём сразу жмём паузу.
* Выставляем фильтр по строке, "journals_comments.php" - теперь в наш архив попадут только те страницы, в адресе которых есть эта строка (то есть левые ссылки наружу из J.Ru не пройдут).
* Неприятный момент: после применения фильтра слетят галки со всех ссылок на страницы, которые мы через Excel насочиняли и в рабочую запись запихали. После применения фильтра их придётся заново протыркать ручками. Это не сложно (они подряд в списке идут), но муторно - функция не автоматизирована и не позволяет помечать несколько страниц за раз. Курсор и пробел в помощь.
* Старт.
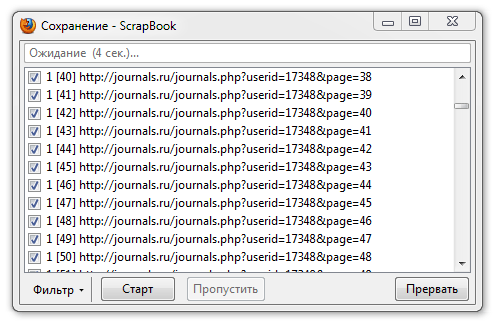
Часть четвёртая.
8) Ждём несколько часов.
9) Архив готов!
У меня получилось полтора гигабайта записей и картинок.
Чтоб открыть его, идём в папку сохранения, далее в папку Data, затем в папку с именем в 10 цифр. Файл index.html поймёт любой веб-браузер. Ну или Фаерфоксом через закладку "Scrapbook" - там появилось имя сохранённого архива.
Дневник со всеми его комментариями сохранён. Можно избавиться от комментариев, можно тащить чужие дневники, можно много чего. Нужно - разберётесь.
Благодарности за помощь с методикой diary-бекапа: MMM, бабер (ака ZaRRaZZa)
Часть первая.
1) Нам потребуется веб-браузер Mozilla Firefox и плагин к нему, Scrapbook. Если не установлены - идём по ссылкам и качаем.
2) Настраиваем место для сохранения нашего архива. В Mozilla Firefox: Инструменты - Дополнения - Scrapbook 1.3.7 - Настройки. Закладка "Организация". Расположение сохраняемой информации - "Сохранить информацию в". Выбираем папку под архив дневника.
3) Заходим в блог через Firefox под своей учётной записью.
4) Определяем, сколько страниц в дневничке уже набалаболено: отправляемся к истокам собственного блоговодства и запоминаем номер последней страницы.
Хинт: На странице своего дневника. Кабинет - Настройки сайта - Общие. Разбиение на страницы / столбцы, в пункте "Записи" ставим значение 25. Меньше мороки будет. Число страниц моего бложека с 498 по умолчанию успешно сократилось до 398.
Часть вторая.
5) Делаем в дневнике рабочую запись со ссылками на все страницы дневника (главная + &page=2, 3 и т.д.).
Хинт: Воспользуемся Excel'ом.
Столбец А: пишем в первую ячейку "1", дальше выделяем в этом столбе строки с первой по 398-ую (т.е. по номеру вашей последней страницы), используем автозаполнение с шагом в единицу (главная - заполнить - прогрессия).
Столбец B: в первую строчку пишем "http://www.journals.ru/journals.php?userid=17348&page=". Дублируем в каждой строчке по 398-ую (последнюю).
Cтолбец С: Пишем текстовую формулу (так же в каждую строчку) "=СЦЕПИТЬ(B:B;A:A)".
Готово. Осталось только скопировать полученное в третьем столбце в запись. Захраняем рабочую запись.
6) Открываем запись в режиме "для печати". (В нижнем правом углу ссылка "Print", если вы её не переименовывали в текстовых настройках дизайна дневника).
Часть третья.
7) Scrapbook'ом сохраняем эту запись. Для чего щёлкаем правой кнопкой мыши по любому пустому месту на записи и выбираем "Захватить веб-страницу как...". Далее:
* Cоставные части страницы: изображения, css-стили.
* Поле "Загрузка содержимого по ссылкам на странице" - отмечаем, планиуем ли грузить всяческие изображения, аудиофайлы, архивы, видео и т.п. Я для себя отметил только изображения.
* Уровень глубины захвата ссылок - 3. Ненужное мы отсечём фильтром.
* Жмакаем "сохранить страницу" и попадаем в новое окно. На нём сразу жмём паузу.
* Выставляем фильтр по строке, "journals_comments.php" - теперь в наш архив попадут только те страницы, в адресе которых есть эта строка (то есть левые ссылки наружу из J.Ru не пройдут).
* Неприятный момент: после применения фильтра слетят галки со всех ссылок на страницы, которые мы через Excel насочиняли и в рабочую запись запихали. После применения фильтра их придётся заново протыркать ручками. Это не сложно (они подряд в списке идут), но муторно - функция не автоматизирована и не позволяет помечать несколько страниц за раз. Курсор и пробел в помощь.
* Старт.
Часть четвёртая.
8) Ждём несколько часов.
9) Архив готов!
У меня получилось полтора гигабайта записей и картинок.
Чтоб открыть его, идём в папку сохранения, далее в папку Data, затем в папку с именем в 10 цифр. Файл index.html поймёт любой веб-браузер. Ну или Фаерфоксом через закладку "Scrapbook" - там появилось имя сохранённого архива.
Дневник со всеми его комментариями сохранён. Можно избавиться от комментариев, можно тащить чужие дневники, можно много чего. Нужно - разберётесь.
Благодарности за помощь с методикой diary-бекапа: MMM, бабер (ака ZaRRaZZa)
Четверг, 3 Февраля 2011 г.
14:55 Mikki Okkolo » О фичах (мечтательно)
А вот хорошо было бы так: идёт флешмоб (напр. тыц , пыц, быц, и ещё много раз), и все (ну, кто захочет) ставят себе такой специльный супертег или какую то метку, тыкая по которой находишь сразу все посты всех камрадов с этим спец-тегом.
Группы: [ Служебная запись ]
Комментарии [10]
Среда, 1 Июля 2009 г.
16:22 Mikki Okkolo » Объявление (призы гиперконкурса)
Просьба отозваться лауреатам прошлогоднего гиперонкурса
Кто получил и, особенно, кто НЕ ПОЛУЧИЛ обещанных призов и ценных подарков?
Как то запустил я этот дело... :(
Кто получил и, особенно, кто НЕ ПОЛУЧИЛ обещанных призов и ценных подарков?
Как то запустил я этот дело... :(
Группы: [ Игры и конкурсы ]
[ Служебная запись ]
Комментарии [12]
Пятница, 26 Декабря 2008 г.
11:03 Mikki Okkolo » Призы призёрам :)

Победители конкурса получают майки с логотипом journals.ru (на рисунке макет, в жизни они намного лучше :) )
Есть чёрные, есть белые. Размер XXL. Выбирайте сами
Просьба девочкам и мальчикам связаться с Artiomenko или с Mikki Okkolo для уточнения способов доставки.
ВОФФЧИК (моё волюнтаристкое решение)
Лохматая
Kanpu3Ka
Ква-кВася
Ромашка
Ромм
Энея
Cler
Niceman
Nikolavna
toskun_i_blyaka
Кто знает, как связаться с Энеей?
Кроме того! Спецпризы!
отредактировано: 26-12-2008 14:53 - Mikki Okkolo
Группы: [ Игры и конкурсы ]
[ Служебная запись ]
Вторник, 16 Декабря 2008 г.
09:02 События » Голосование остановлено
Начинается подсчёт голосов.
Победители будут объявлены в пятницу.
Победители будут объявлены в пятницу.
отредактировано: 16-12-2008 09:02 - События
Группы: [ Служебная запись ]
Четверг, 11 Декабря 2008 г.
09:29 События » Завершение голосований
В связи с тем, что голосования в рамках мультиконкурса практически остановились, в понедельник 15 декабаря они будут остановлены.
Итоги будут объявлены в конце следующей недели.
Итоги будут объявлены в конце следующей недели.
Группы: [ Служебная запись ]
Комментарии [3]
Понедельник, 8 Декабря 2008 г.
13:19 События » Обновился поплавок
Изменён адрес "Консультации" -- теперь это клуб.
Добавлены ссылки на всякие интересные штуки:
Образцы почерка камрадов
Детские фотографии камрадов
Семейные пары
+
Камрады в рисунках tDO
Дни рождения
Добавлены ссылки на всякие интересные штуки:
Образцы почерка камрадов
Детские фотографии камрадов
Семейные пары
+
Камрады в рисунках tDO
Дни рождения
отредактировано: 15-12-2008 11:20 - События
Группы: [ Служебная запись ]
Комментарии [3]
Вторник, 25 Ноября 2008 г.
13:29 События » Последний этап гиперконкурса
голосование продлится до 22 декабря.
Открыты голосования за лучших из лучших в номинациях:
Перо года
Фотограф года
Родитель года
Женщина года
Мужчина года
Секс-символ года
Загадка года
Мудрец года
Комментатор года
Потеря года
Открытие года
Клуб года
Улыбка года
Победителей ждут ПРИЗЫ!
Открыты голосования за лучших из лучших в номинациях:
Перо года
Фотограф года
Родитель года
Женщина года
Мужчина года
Секс-символ года
Загадка года
Мудрец года
Комментатор года
Потеря года
Открытие года
Клуб года
Улыбка года
Победителей ждут ПРИЗЫ!
отредактировано: 25-11-2008 13:44 - События
Четверг, 6 Ноября 2008 г.
11:31 События » Продолжаем гиперконкурс
Ну что, задремали в бурой тине?
Начинаем второй этап наших выборов! Он продлится до конца ноября.
Предлагайте участников для каждой из номинаций, вышедшей в десятку лидеров.
Как это сделать: клик на номинации, например, на «Секс-символ года»; попадаете в соответствующую запись — и в комментах оставляете имя своего избранника (можно нескольких, количество не ограничено). Обязательно! — оформляйте ник ссылкой на дневник. (Как оформить ник ссылкой)
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём.
Если повторите уже названное имя — тоже не страшно.
Все предложенные кандидатуры пройдут в третий этап, т.е. непосредственно к финальному голосованию, которое будет проводиться в течение декабря.
Перо года
Фотограф года
Родитель года
Женщина года
Мужчина года
Секс-символ года
Загадка года
Мудрец года
Потеря года
Комментатор года
Улыбка года
Клуб года
Открытие года
Внимание! Призы!
Для победителей в некоторых номинациях уже есть призы! Пока это — четыре бутылки вкусной и полезной огненной воды от Милославского, МММ и М.О. Но есть все основания полагать, что этот список будет расширен. Следите за объявлениями!
Более подробно
Начинаем второй этап наших выборов! Он продлится до конца ноября.
Предлагайте участников для каждой из номинаций, вышедшей в десятку лидеров.
Как это сделать: клик на номинации, например, на «Секс-символ года»; попадаете в соответствующую запись — и в комментах оставляете имя своего избранника (можно нескольких, количество не ограничено). Обязательно! — оформляйте ник ссылкой на дневник. (Как оформить ник ссылкой)
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём.
Если повторите уже названное имя — тоже не страшно.
Все предложенные кандидатуры пройдут в третий этап, т.е. непосредственно к финальному голосованию, которое будет проводиться в течение декабря.
Перо года
Фотограф года
Родитель года
Женщина года
Мужчина года
Секс-символ года
Загадка года
Мудрец года
Потеря года
Комментатор года
Улыбка года
Клуб года
Открытие года
Внимание! Призы!
Для победителей в некоторых номинациях уже есть призы! Пока это — четыре бутылки вкусной и полезной огненной воды от Милославского, МММ и М.О. Но есть все основания полагать, что этот список будет расширен. Следите за объявлениями!
Более подробно
отредактировано: 07-11-2008 09:34 - События
11:24 События » номинация «Комментатор года»!
Комментатор года
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:54 - События
11:22 События » номинация «Потеря года»! :(
Потеря года 
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:54 - События
11:21 События » номинация «Мудрец года»!
Мудрец года
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:54 - События
11:20 События » номинация «Загадка года»!
Загадка года
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:53 - События
Комментарии [17]
11:18 События » номинация «Секс-символ года»!
Секс-символ года
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:53 - События
11:17 События » номинация «Мужчина года»!
Мужчина года
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
Предлагайте участников.
Обязательно! — оформляйте ник ссылкой на дневник.
Если напишете, почему данная кандидатура достойна стать победителем конкурса — отлично. Не напишете — не страшно, сами поймём. Если повторите уже названное имя — тоже не страшно.
Голосование по всем предложенным кандидатурам пройдёт в течение декабря.
О приёме кандидатур в другие номинации
отредактировано: 06-11-2008 11:53 - События
Клуб посткроссинга.
[Print]
Гость